Avances hito 2
Este parte del informe relata los avances del proyecto respecto de la entrega pasada. Para empezar se realizará un breve resumen del tema escogido. El tema elegido es el de realizar un predictor de ganadores de los Premios Oscar, esto implica dque se usaran bases de datos de distintas películas ganadoras y no ganadoras de premios, que contendrán atributos de distintas caracteristicas, para poder decifrar algunos factores que hagan mayor la posibilidad de que gane un premio en este festival. Como inicio de pruebas se elaboro un dataset con datos faciles de usar, como son el nombre de la pelicula, nominaciones en otros eventos, etc. Utilizando la clase inicial de "gano_oscar"Después de reconocer el dataset observaremos la cantidad de datos distintos entre ganadores y no ganadores de premios Oscar, con lo que se obtuvo la siguiente imagen:.

En esta etapa se decide utilizar un clasificador para poder, obviamente, clasificar peliculas posiblementes ganadoras de un premio. Para usar un clasificador a continuación se elimina los atributos que son innecesarios para el clasificador. Aquellos son eliminados en el siguiente cuadro.

Para un clasificador es muy dificil tratar con numeros demasiados grandes, por eso se eligió una simplificación donde se restará presupuesto a revenue, esto generando un 1 si es positiva la suma y un 0 si no lo es. Estos valores serán dejados en un nuevo atributo que se llamará "ganancia"

Luego por recomendación de algunos compañeros, se transforma el lenguaje original de la película para que el clasificador pueda actuar de mejor forma.

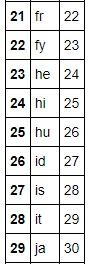
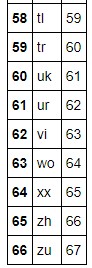
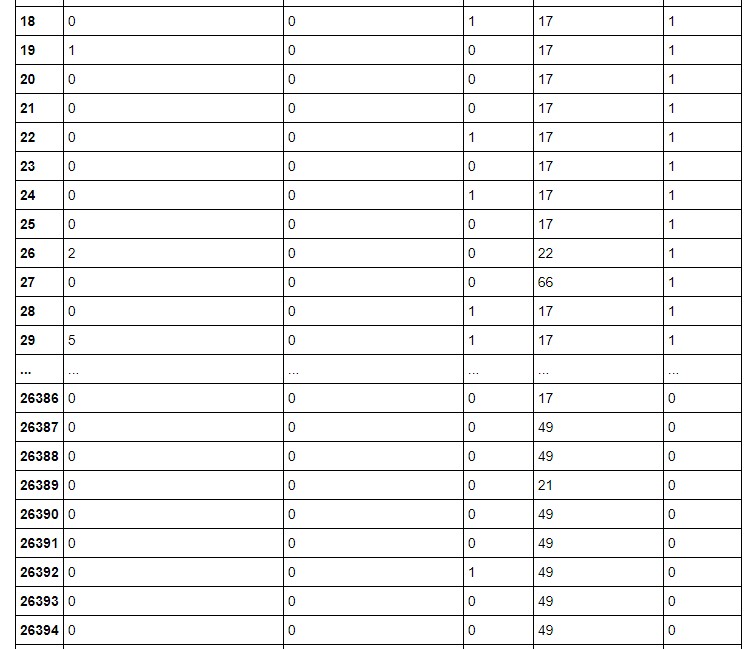
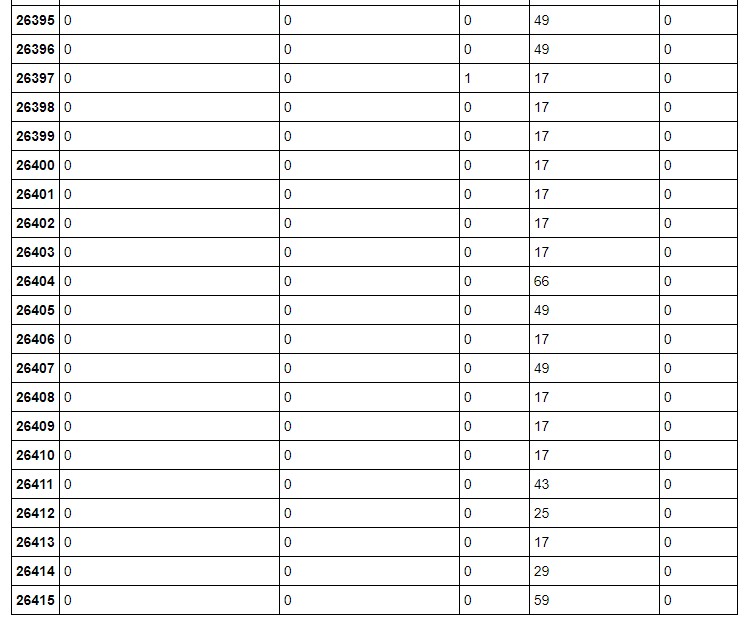
Se muestra la tabla que relaciona lenguaje original con los números.


Terminando lo anterior, nos fijamos que existían algunos atributos que pueden ser afectar de manera subjetiva al clasificador, por ello eliminamos la columna "popularity", y además la columna "premios en los oscar", debido que para un efectivo entrenamiento no puede existir una relación directa entre clases y sus atributos.
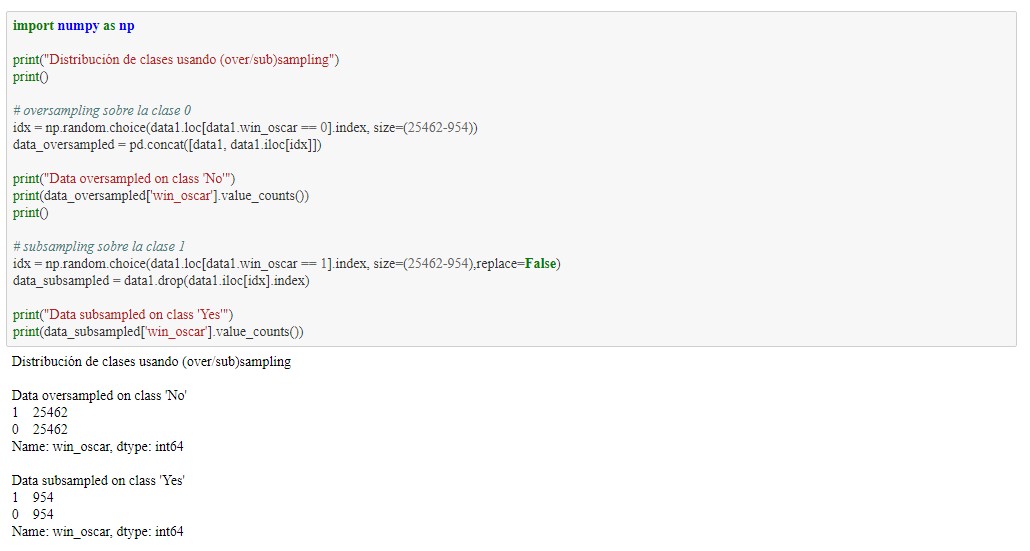
Se vuelve a observar la heteromogeneidad de la clase, resultando con 25462 ganadores de Oscar, mientrás solo 954 no ganadores. Lo que puede generar error en el clasificador con esta diferencia. Es por lo anterior que se genera pruebas utilizando over y sub sampling.
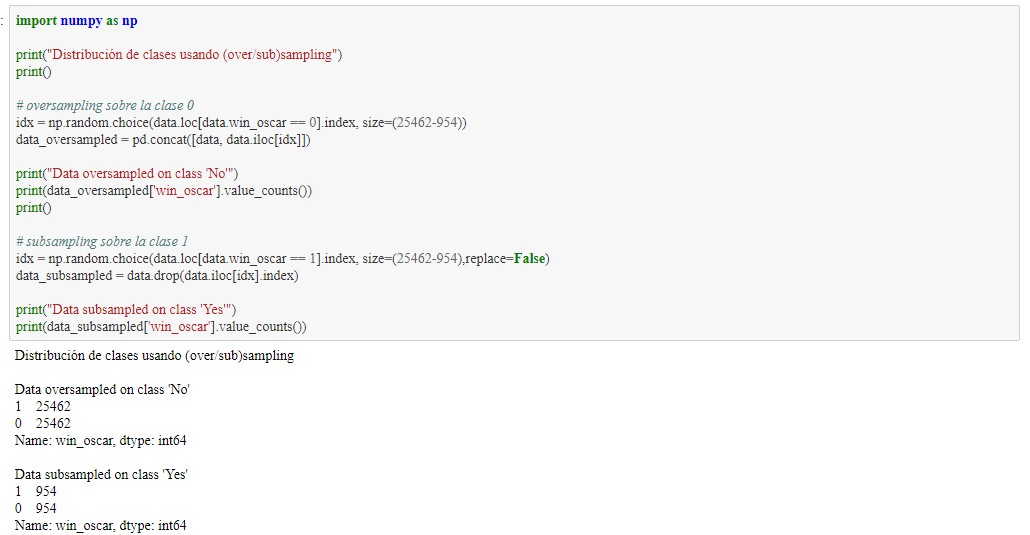

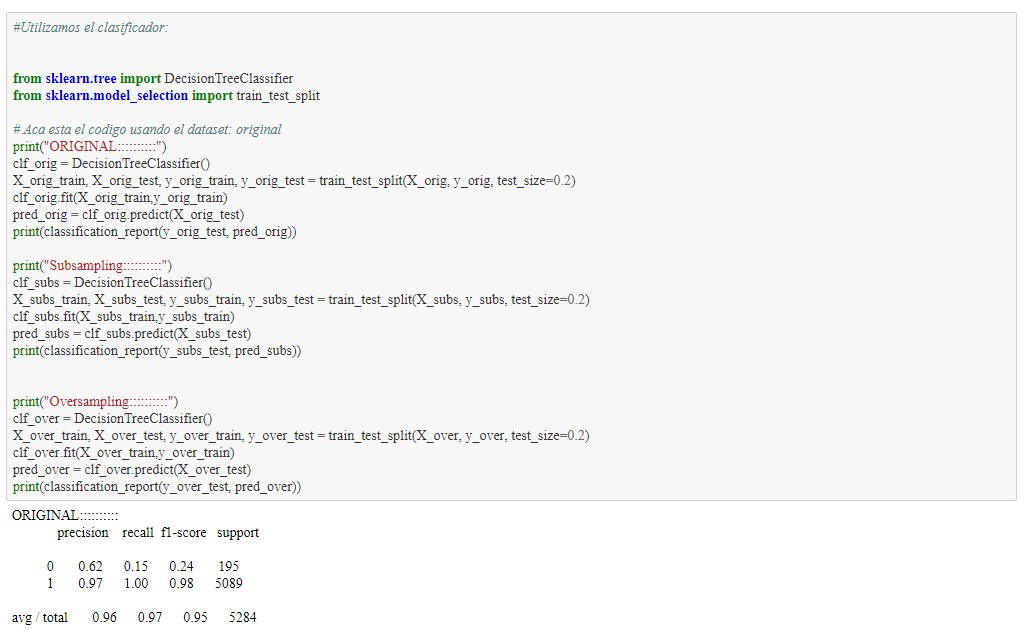

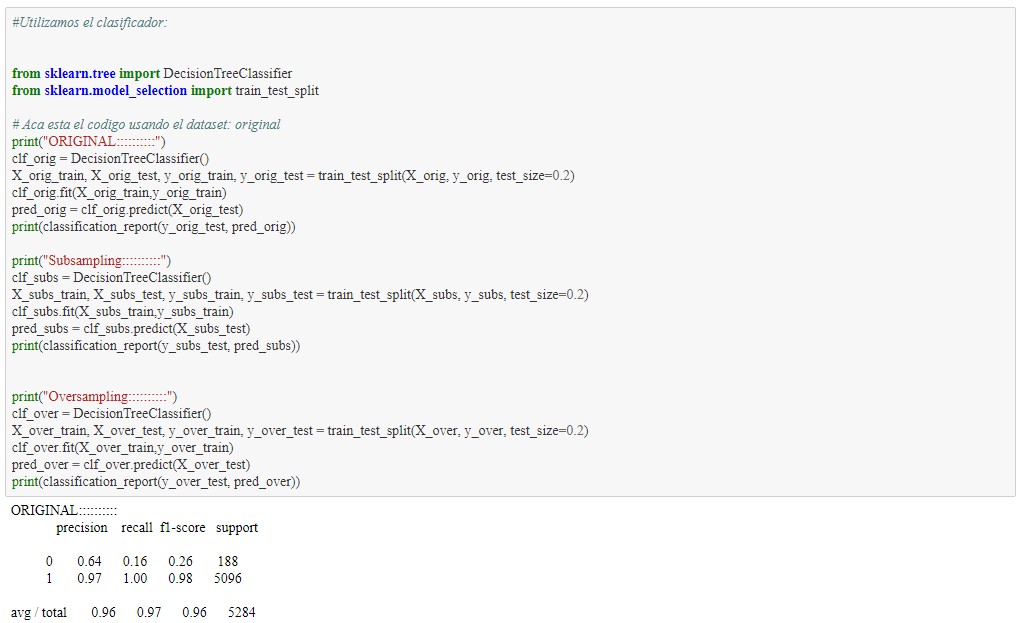
Se observa extrañamente que el mejor caso es el original con gran diferencia de las clases, este tema deberá ser estudiado más a profundo para avanzar en el estudio del proyecto. Además de esto llama la atención los resultados tan buenos que este entrega, siendo casi todos los valores mayores a 80% de exito. A continuación se elimina "las nominaciones a los oscar", debido a la existencia de una posible dependencia grande.
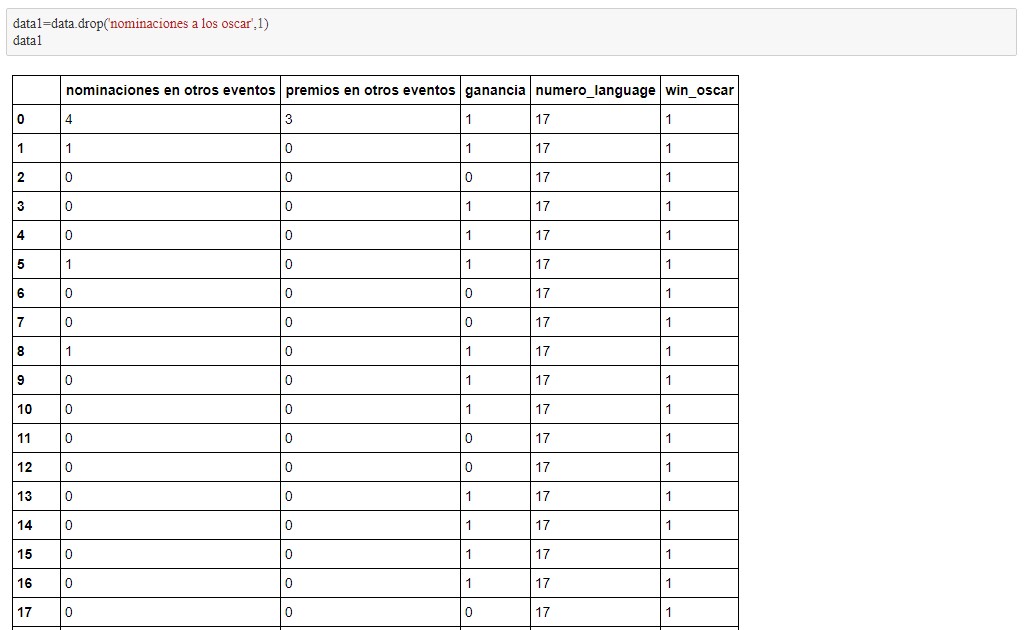


Aunque se haya quitado los factores directos de los ganadores de los Oscar, parece ser que el clasificador esta realizando su trabajo de manera correcta. Para continuar el trabajo se plantea realizar un estudio más a profundo de estos resultados, además de utilizar algunos otros clasificadores. Finalmente se desea poder diferenciar ganadores de por lo menos 4 categorías, para esto se debera seguir intentado agregar datos de entrenamiento.